While dealing with files data in TIBCO BW, you often come across situations where large files have duplicate data and you want to process only duplicate-free data. In this TIBCO For Each Group tutorial, I will explain how we can read data from a file, parse the data based on a data format and then use For-each group statement in a mapper to remove duplicates from the records.
Example Scenario for TIBCO For Each Group Tutorial:
We have a file (order.txt) which contains Orders data in the form of Product Name and Product Price in comma separated format as shown below:
mobile,410
watch,30
laptop,5000
mouse,20
printer,50
mobile,410
watch,30
As you can see the above example data, we have duplicate entries for the products like mobile and watch. We will go step by step to write a TIBCO process that will read this data from the file, parse it and then using a mapper, we will get duplicate-free data.
Let’s proceed step by step with the tutorial.
Step 1: Create Data Format for Comma Separated File Data
As we will be reading comma separated data from the orders.txt file, we need to define a Data Format in our project by using Data Format resource from the Parse Palette.
In the configuration tab of Data Format, specify Delimiter Separated as Format Type and use Comma (,) as a Column Separator. Also choose Carriage Return/Line Feed as Line Separator as shown in screenshot below:
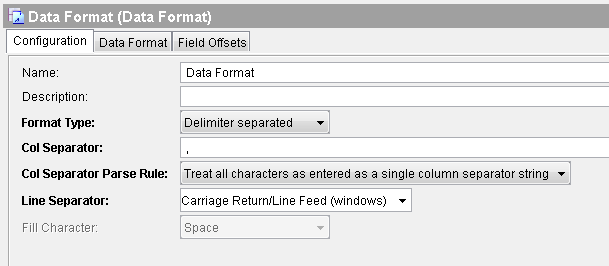
Next, move to Data Format tab and define the format of the data. For our case, we have orders data with Product Name and Price values, so we define Data Format Schema accordingly as shown in below screenshot:
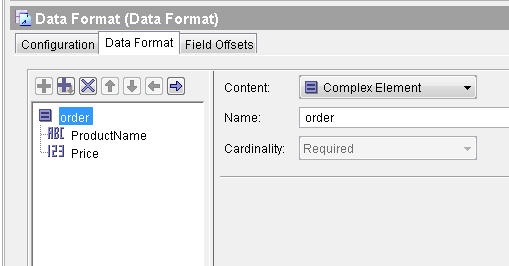
Step 2: Create Tibco Process to Read File, Parse Data and Remove Duplicate Records
Create a new process in your designer project. Add a Read File activity to read orders data. In the Input tab of this Read File activity, specify the full path of the file to be read as shown below:
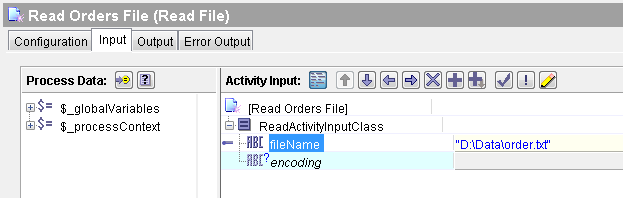
After Read File activity, add Parse Data activity from the Parse Palette in your process. In the configuration of Parse Data activity, choose the Data Format (that we created in Step 1) as you can see in screenshot below:
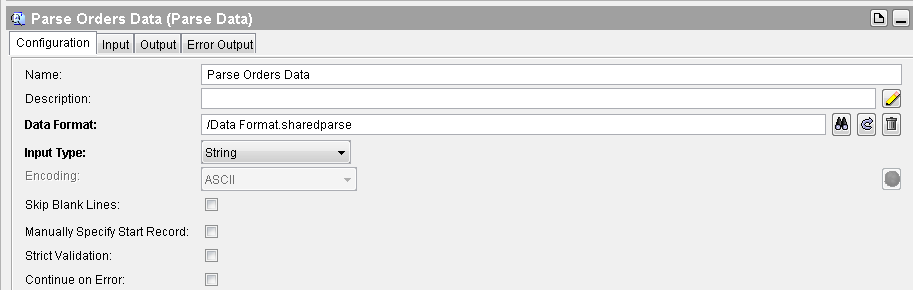
The next thing that we are going to do is the actual step which will do the needful. In this step, we will add a Mapper in our process and then use for-each-group statement to remove duplicate orders that we have parsed already.
In the Input Editor tab of the Mapper, define a complex element with the elements for order details (ProductName and Price) as shown below:
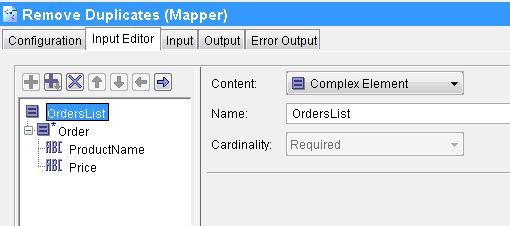
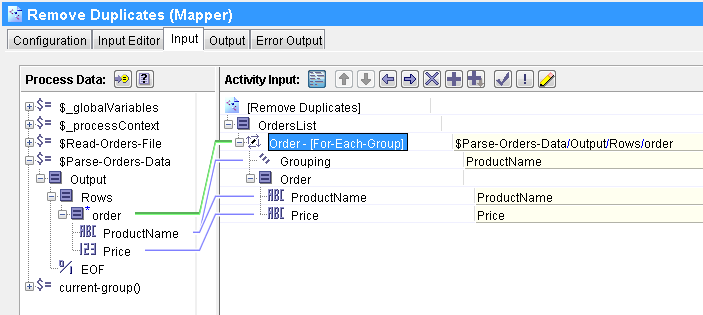
Now go to the Input tab and right click on Order Element. Choose Statement–>Surround with For-each-group option. After this, map Parse Data output’s order element to it. As we want to get only unique orders based on the product name, we use ProductName element in the Grouping field. Also map, ProductName and Price elements to the schema.
The complete input mapping is shown below:
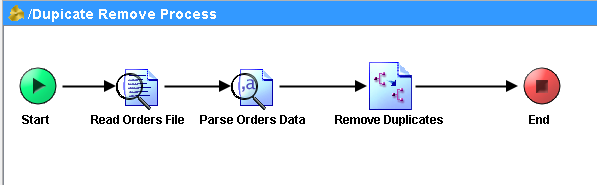
This completes configurations and mappings for all the activities in our process. Complete process will now look like below:
Now let’s proceed to the next step in which we will run the process in designer tester and see the results.
Step 3: Test TIBCO Process to remove Duplicate Data
Load the process in the designer tester so that Its job is created. As you can see below, process has run successfully and Parse Data has given output with all the orders from the file (duplicates included):

And now if you see the output of Mapper, you can see that It has given duplicate free output by removing duplicates:
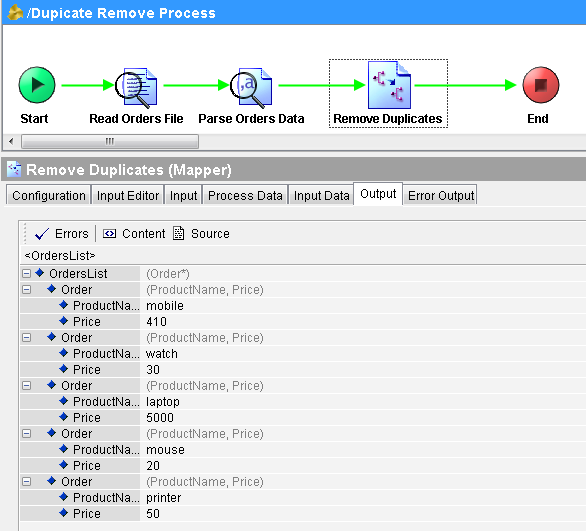
This completes the tutorial. I hope it was beneficial for you and you liked it. Feel free to contact me for any further help.
Excellent Sir.
Through mappers how can we remove the duplicates could you explain briefly sir Please?
For the orders root element in the input tab of Mapper activity, create a “for_each_group” and not for each . This will provide a grouping text box below, where you can give product name not to get duplicated
Hi Sir,
Parse Data pallette’s Input tab is showing error.
How to rectify that?
Please share the screenshot for Input tab as well.
In the input tab provide the file name which you have used in the read file activity and give the count down to that as 7.
Your comment is awaiting moderation.
In Parse Data pallette’s Input tab map text with read file text content for eg:
($Read-File/ns:ReadActivityOutputTextClass/fileContent/textContent)
and in number of records hard code with “-1”.
Hi Aditi ,
Thank you so much ,this works for me
In Parse Data pallette’s Input tab map text with read file text content for eg:
($Read-File/ns:ReadActivityOutputTextClass/fileContent/textContent)
and in number of records hard code with “-1”.
You need to specify the ‘textContent’ and ‘noOfRecords’ : textContent being the text from the file (order.txt, here)you want to parse and noOfRecords is the total no of records you want to read from the input stream(enter -1 to read all records from the input stream)
In the mapper activity — order(for-each-group) showing—-like formula has error
plz give me the solution.
You need to specify the ‘textContent’ and ‘noOfRecords’ : textContent being the text from the file (order.txt, here)you want to parse and noOfRecords is the total no of records you want to read from the input stream(enter -1 to read all records from the input stream)
As like siva’s error i got..
In the mapper activity — order(for-each-group) showing—-like formulas has error
plz give me the solution…
Hi Sir,
I need a help for similar problem like above. My xml looks like this,
564593
565028
565031
601687
565027
O
565028
564593
O
565028
565031
601687
621016
564593
O
565027
565028
565029
565031
564593
O
565027
565028
565031
601687
564593
O
As you can note ClientID – 564593 has clientrole values such as empty string,o,o,o,o when i use for-each-group I am able to get only
564593
But i need
564593
564593
O
Similarly for all client IDs. Please provide me a solution.
Hi,
If any one completed this steps without facing any issue . Please check and help me out . Mapper activity is throwing mapping error in input tab for order- [For-Each-Group] expecting non repeating got repeating .
In mapper, in the Input Editor tab, try giving the value ‘repeating(*)’ in the Cardinality for Order . It is not mentioned or shown in this article.
it gives very confusing in mappers
what operation u did how u did its getting confused could explain clearly
This is a good example, but what if I want to pick up the product has the highest Price? I tried to use the max() function, but can’t get it work. Thanks
input:
mobile,410
watch,30
laptop,5000
mouse,20
printer,50
mobile,415
watch,40
output:
laptop,5000
mouse,20
printer,50
mobile,415
watch,40
In that case u would require to use Process variable to store the previous highest value while comparing that with current value. In case if current one turns out as higher then replace the process variable value with it, by this way at the end of the Group (iterate), we could map the highest value of the product.
This is a good example
Hello Ajmal
A very helpful example. However, I was wondering to do a summation operation for the duplicate Product name. for instance on mobile and I was trying to add the 2 prices. could you please tell me a way to do that. I tried a lot of options but I am not able to do.
Thanks in advance!
Pingback: TIBCO XPath Tips | Joys Of My Life
why you have used “Carriage Return/Line Feed as Line Separator”
1.can you explain the line separator types and their usage?
Fokls use this simple XSL it will work, easy in one shot, faster. It can be extended to any XML in Tibco using XSLT/XSL palette, it can also be used in any other technology, mulesfot, nodejs, apigee, etc etc
******GET THE VALUES INTO AN XML LIKE THIS*****
******* BEFORE TRANSFORMATION*****
mobile,410
watch,30
laptop,5000
mouse,20
printer,50
mobile,410
watch,30
******* BEFORE TRANSFORMATION*****
******XSLT CODE*****
******XSLT CODE*****
******* AFTER TRANSFORMATION*****
mobile,410
watch,30
laptop,5000
mouse,20
printer,50
******* AFTER TRANSFORMATION*****
Thank You,
Varun,
linkedin.com/in/varunkk